

Tôi đã tạo ra "bộ não thứ 2" với Obsidian + Claude code (đây là hướng dẫn chi tiết)

Thời gian vừa qua tôi thực sự đã tạo ra một bộ não thứ hai bằng trí tuệ nhân tạo, tôi đưa tất cả những gì trong quá khứ vào đó. Nó chứa đựng suy nghĩ, những gì tôi đọc, viết, nhìn, nghe, nghiên cứu trực tuyến và hơn thế nữa.
Và từ nay tôi sẽ tiếp tục đưa vào bộ não thứ 2 này những kế hoạch kinh doanh, cuộc sống, ngay cả mục đánh dấu trang, ứng dụng ghi chú, ảnh chụp màn hình, cuốn sách đã đọc, bài báo đã lưu ghi chú, cuộc họp… để nó ngày càng thông minh hơn, hiểu tôi hơn. Làm được nhiều việc giống như tôi làm hơn.
Bộ não thứ 2 này sẽ giải quyết vấn đề không phải là bạn không thu thập thông tin. Bạn đã làm điều đó rồi. Vấn đề là bạn không thể tìm thấy bất kỳ thông tin nào khi cần.
Bộ não thứ 2 đóng vai trò như một kho kiến thức cá nhân sẽ giải quyết vấn đề này vĩnh viễn.
Bạn chỉ cần tập hợp mọi thứ vào một chỗ, đưa trí tuệ nhân tạo (AI) vào đó, và nó sẽ sắp xếp mớ hỗn độn thành một wiki của riêng bạn có thể tìm kiếm, và wiki này sẽ ngày càng thông minh hơn mỗi khi bạn sử dụng.
Đặt vấn đề & bối cảnh
Bạn có bao giờ bực mình khi bắt đầu một chat AI mới, rồi lại phải gõ: “Tôi là blogger, tên Ngọc, 10 năm trước tôi viết về marketing và kiếm tiền online ở ngocdenroi.com . Bây giờ tôi viết về AI - Tài chính - Gia đình 4.0 ở Chạm.media...”?
Tôi đã làm điều đó nhiều lần. Mỗi chat mới là một trang trắng. AI không biết tôi là ai. Không nhớ bài tôi đã viết tuần trước. Không biết CHẠM.media là gì. Không biết kế hoạch tháng sau của tôi.
...Và tôi cứ nghĩ đó là chuyện bình thường.
Rồi đến một ngày tôi đọc được một tweet của Andrej Karpathy, đây là người từng dẫn dắt nhóm AI tại Tesla, một trong những AI researcher có ảnh hưởng nhất thế giới. Ông chia sẻ về ý tưởng xây dựng một “LLM Knowledge Base” cá nhân, nơi AI không phải tìm kiếm lại từ đầu mỗi lần bạn hỏi, mà thay vào đó: tích lũy và kết nối kiến thức theo thời gian.

Sau khi đọc kỹ, tham khảo một số bai viết khác tôi đã tự xây cho mình một hệ thống, một bộ não thứ 2 như vậy. Mất khoảng một buổi sáng. Và tôi muốn chia sẻ từng bước để bạn có thể làm tương tự - việc setup trong 30 phút (chưa kể thời gian nhập dữ liệu thô), không cần biết code, kể cả khi bạn chưa bao giờ nghe đến Obsidian hay markdown, Clade code.
Trước khi vào cài đặt để tôi giải thích thêm một chút:
Vấn đề thực sự với AI hiện tại: mỗi lần bắt đầu là mất trắng ngữ cảnh
Hầu hết cách chúng ta dùng AI hiện nay đều giống nhau: upload file, đặt câu hỏi, nhận câu trả lời. Rồi đóng chat.
Lần sau mở chat mới, AI không nhớ gì. Bạn phải upload lại, giải thích lại, cung cấp context (ngữ cảnh) lại. Mỗi lần như vậy tốn thêm 5-10 phút chỉ để “dạy” AI biết bạn là ai. (thậm chí việc này rất tốn token - mà token bạn phải trả qua gói đăng ký hàng tháng đó)
Karpathy gọi đây là vấn đề của RAG (Retrieval Augmented Generation) truyền thống: AI chỉ “truy xuất thông tin khi cần” nhưng không bao giờ thực sự tích lũy từ những lần trước. Hỏi một câu phức tạp đòi hỏi tổng hợp từ 5 tài liệu khác nhau AI phải làm lại từ đầu mỗi lần.
Hệ thống ông đề xuất khác hẳn: thay vì để AI tìm kiếm từ tài liệu thô mỗi lần bạn hỏi, AI xây dựng và duy trì một wiki có cấu trúc đây là bộ kiến thức được tổ chức, liên kết với nhau, và ngày càng phong phú hơn khi bạn thêm dữ liệu mới.
“Đây là điểm khác biệt quan trọng: wiki này là một tài sản tích lũy theo thời gian, không phải thứ phải làm lại từ đầu mỗi lần.” — Andrej Karpathy
Ba lớp của hệ thống & vai trò của từng lớp
Trước khi đi vào hướng dẫn, hiểu được kiến trúc của bộ não thứ 2 sẽ giúp bạn làm đúng ngay từ đầu.
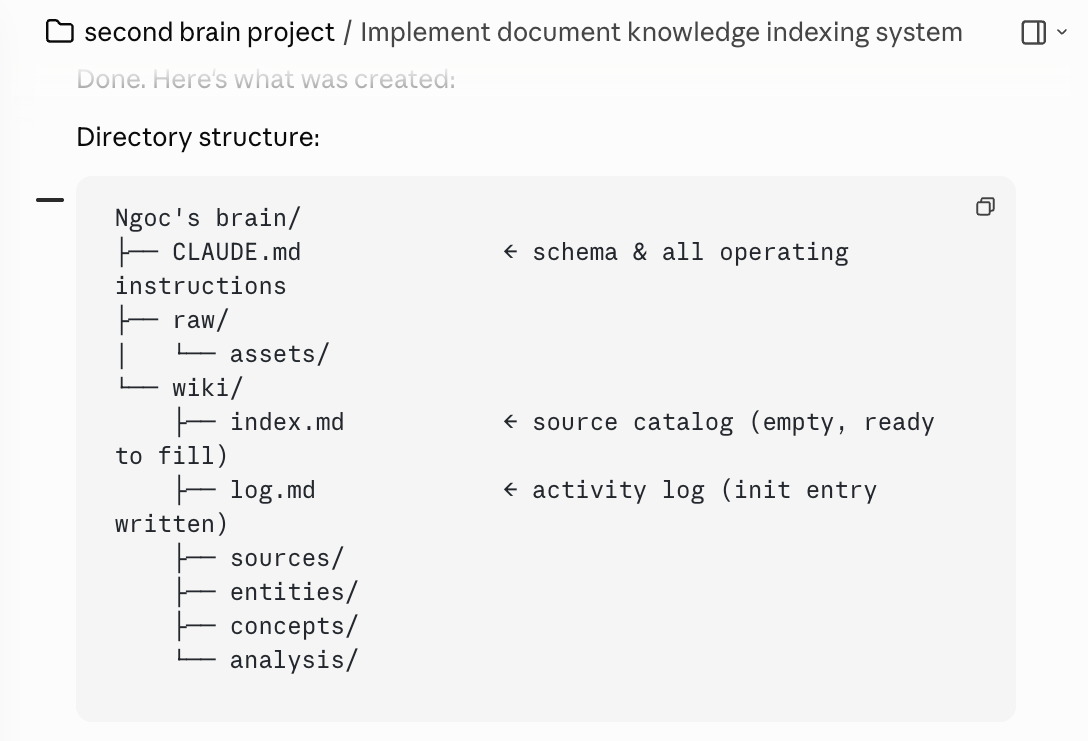
Lớp 1 - Raw Sources (nguồn thô): Tất cả dữ liệu của bạn bào gồm bài viết, ghi chú, transcript, ý tưởng, bookmark, trang sách, hình ảnh... Đây là “nguồn sự thật” bất biến. AI chỉ đọc, không chỉnh sửa.
Lớp 2 - Wiki: Nơi AI tạo và duy trì các file markdown có cấu trúc được tóm tắt từng trang theo chủ đề, khái niệm, dự án, kết nối ý tưởng. AI “sở hữu” lớp này và nó tạo, cập nhật, duy trì. Mỗi khi bạn thêm tài liệu mới, AI không chỉ lưu nó mà còn tích hợp vào wiki hiện có, cập nhật các trang liên quan, ghi nhận điểm mâu thuẫn với kiến thức cũ.
Lớp 3 - Schema (CLAUDE.md): File hướng dẫn cho AI biết wiki được tổ chức thế nào, quy ước ra sao, cần làm gì khi có tài liệu mới. Đây là “bộ não” của bộ não, cái làm cho AI trở thành wiki maintainer (một wiki cá nhân được quản lý, cập nhật, bảo trì) có kỷ luật thay vì chatbot thông thường.
Khi bạn cài đặt, Obsidian (ứng dụng ghi chú và quản lý tri thức cá nhân) chứa cả ba lớp này. Claude sẽ được kết nối với thư mục vault, đóng vai trò người quản lý và mở rộng wiki theo thời gian.
Thôi dài dòng vậy đủ rồi, vào việc nha. Lấy một ly nước, hít một hơi thật sâu để chuẩn bị tạo ra một… bộ não thứ 2 của bạn
Hướng dẫn từng bước: tự xây bộ não thứ 2 trong 30 phút
Đây là đúng những gì tôi đã làm sáng hôm nay - một người không biết code, một người đã ngoài 40 tuổi :))
Bước 1: Tải Obsidian và tạo Vault
Truy cập obsidian.md/download và tải ứng dụng về. Obsidian miễn phí, hoạt động hoàn toàn offline. Dữ liệu lưu trên máy tính của bạn dưới dạng file “.md” (markdown) không phải trên server của ai cả. Đây là điều tôi thích nhất: dữ liệu của bạn, ở máy của bạn, mãi mãi.
Đọc nhanh: Obsidian là ứng dụng ghi chú và quản lý tri thức cá nhân (PKM) mạnh mẽ, hoạt động trên các tệp văn bản thuần túy (Markdown) lưu trữ trực tiếp trên thiết bị (offline). Nó nổi bật với khả năng liên kết các ghi chú tạo thành một "bộ não thứ hai" mạng lưới, miễn phí cho cá nhân, đa nền tảng (Win, Mac, Linux, iOS, Android) và tùy biến cao qua plugin.
Sau khi cài, bạn thấy màn hình chọn vault. Chọn “Tạo khối lưu trữ mới”. Đặt tên gì cũng được, vault của tôi tên là “Ngoc’s brain”. Chọn thư mục bạn muốn lưu, tôi thì đặt vị trí lưu trên Desktop cho tiện thao tác.
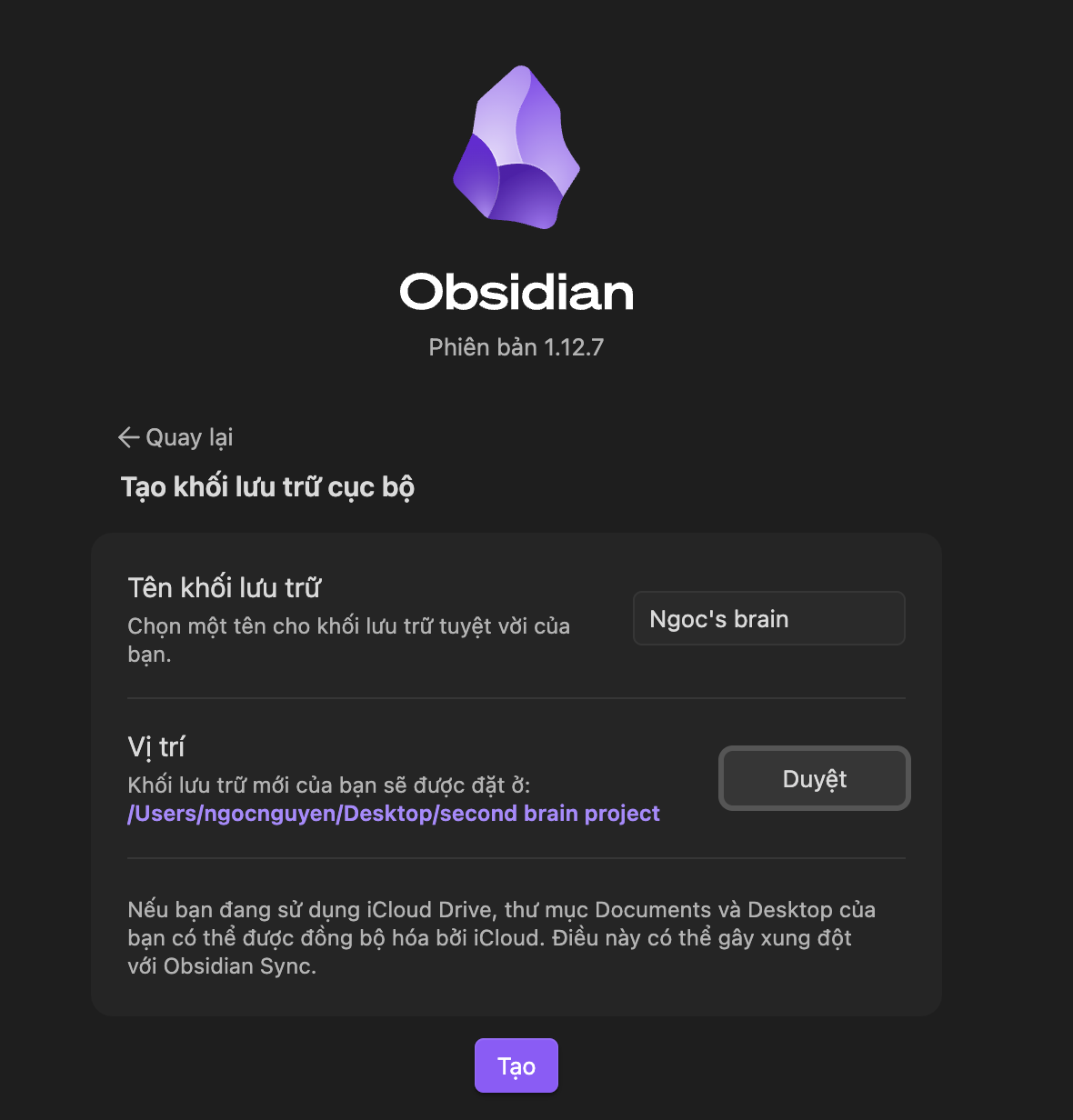
Obsidian mở ra với một note “Chào mừng” và Graph View trống bên phải. Graph View chính là màn hình bạn sẽ thấy vault mình “lớn lên” khi các ghi chú bắt đầu kết nối với nhau thành một mạng lưới.
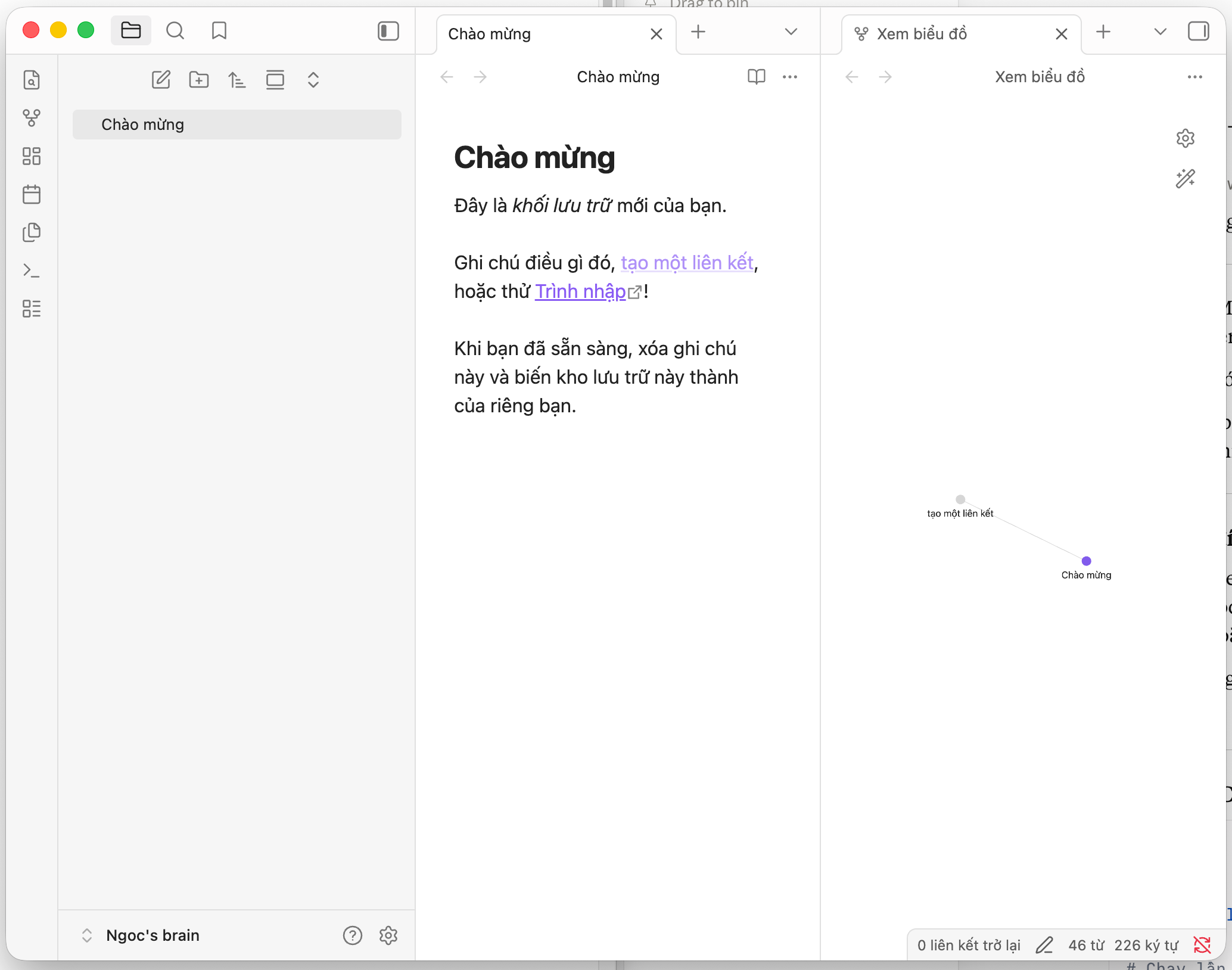
Bước 2: Mở Claude Code và kết nối với Vault
Bước này nếu bạn nào chưa dùng Claude bao giờ thì tạm ngừng để đọc & cài Claude Cowork theo bài hướng dẫn dưới đây nha:

Mở Claude Code (desktop app). Ở màn hình chính, click “Select Folder” và chọn thư mục vault Obsidian vừa tạo
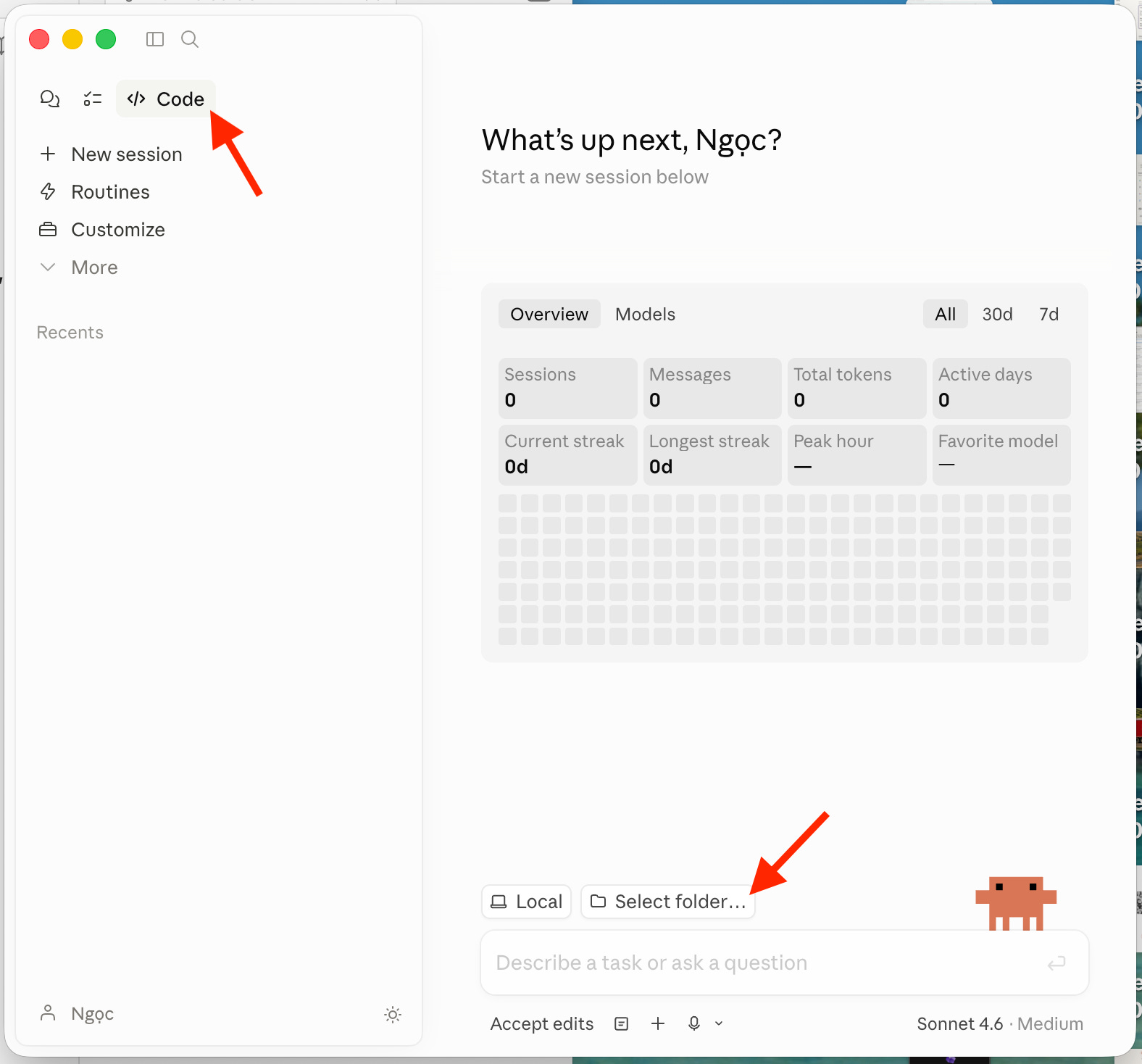
Bước này quan trọng: Claude giờ có quyền đọc và ghi vào thư mục vault. Nó có thể tạo file, chỉnh sửa, tổ chức cấu trúc và tất cả đều xuất hiện trực tiếp trong Obsidian. Hai ứng dụng “nói chuyện” với nhau qua chính thư mục đó. Không cần plugin, không cần API key, không cần cấu hình thêm gì.
Bước 3: Dán System Prompt của Karpathy, đây là bước “ma thuật”
Copy đoạn system prompt dưới đây. Đây là prompt từ gist trên github của Karpathy bạn chỉ cần dán vào chatbox của Claude:
The core idea
Most people's experience with LLMs and documents looks like RAG: you upload a collection of files, the LLM retrieves relevant chunks at query time, and generates an answer. This works, but the LLM is rediscovering knowledge from scratch on every question. There's no accumulation. Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up. NotebookLM, ChatGPT file uploads, and most RAG systems work this way.
The idea here is different. Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent wiki — a structured, interlinked collection of markdown files that sits between you and the raw sources. When you add a new source, the LLM doesn't just index it for later retrieval. It reads it, extracts the key information, and integrates it into the existing wiki — updating entity pages, revising topic summaries, noting where new data contradicts old claims, strengthening or challenging the evolving synthesis. The knowledge is compiled once and then kept current, not re-derived on every query.
This is the key difference: the wiki is a persistent, compounding artifact.
There are three layers:
Raw sources — your curated collection of source documents. Articles, papers, images, data files. These are immutable — the LLM reads from them but never modifies them. This is your source of truth.
The wiki — a directory of LLM-generated markdown files. Summaries, entity pages, concept pages, comparisons, an overview, a synthesis. The LLM owns this layer entirely. It creates pages, updates them when new sources arrive, maintains cross-references, and keeps everything consistent. You read it; the LLM writes it.
The schema — a document (e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex) that tells the LLM how the wiki is structured, what the conventions are, and what workflows to follow when ingesting sources, answering questions, or maintaining the wiki. This is the key configuration file — it's what makes the LLM a disciplined wiki maintainer rather than a generic chatbot. You and the LLM co-evolve this over time as you figure out what works for your domain.
Operations
Ingest. You drop a new source into the raw collection and tell the LLM to process it. An example flow: the LLM reads the source, discusses key takeaways with you, writes a summary page in the wiki, updates the index, updates relevant entity and concept pages across the wiki, and appends an entry to the log. A single source might touch 10-15 wiki pages. Personally I prefer to ingest sources one at a time and stay involved — I read the summaries, check the updates, and guide the LLM on what to emphasize. But you could also batch-ingest many sources at once with less supervision. It's up to you to develop the workflow that fits your style and document it in the schema for future sessions.
Query. You ask questions against the wiki. The LLM searches for relevant pages, reads them, and synthesizes an answer with citations. Answers can take different forms depending on the question — a markdown page, a comparison table, a slide deck (Marp), a chart (matplotlib), a canvas. The important insight: good answers can be filed back into the wiki as new pages. A comparison you asked for, an analysis, a connection you discovered — these are valuable and shouldn't disappear into chat history. This way your explorations compound in the knowledge base just like ingested sources do.
Lint. Periodically, ask the LLM to health-check the wiki. Look for: contradictions between pages, stale claims that newer sources have superseded, orphan pages with no inbound links, important concepts mentioned but lacking their own page, missing cross-references, data gaps that could be filled with a web search. The LLM is good at suggesting new questions to investigate and new sources to look for. This keeps the wiki healthy as it grows.
Indexing and logging
Two special files help the LLM (and you) navigate the wiki as it grows. They serve different purposes:
index.md is content-oriented. It's a catalog of everything in the wiki — each page listed with a link, a one-line summary, and optionally metadata like date or source count. Organized by category (entities, concepts, sources, etc.). The LLM updates it on every ingest. When answering a query, the LLM reads the index first to find relevant pages, then drills into them. This works surprisingly well at moderate scale (~100 sources, ~hundreds of pages) and avoids the need for embedding-based RAG infrastructure.
log.md is chronological. It's an append-only record of what happened and when — ingests, queries, lint passes. A useful tip: if each entry starts with a consistent prefix (e.g. ## [2026-04-02] ingest | Article Title), the log becomes parseable with simple unix tools — grep "^## \[" log.md | tail -5 gives you the last 5 entries. The log gives you a timeline of the wiki's evolution and helps the LLM understand what's been done recently.
Optional: CLI tools
At some point you may want to build small tools that help the LLM operate on the wiki more efficiently. A search engine over the wiki pages is the most obvious one — at small scale the index file is enough, but as the wiki grows you want proper search. qmd is a good option: it's a local search engine for markdown files with hybrid BM25/vector search and LLM re-ranking, all on-device. It has both a CLI (so the LLM can shell out to it) and an MCP server (so the LLM can use it as a native tool). You could also build something simpler yourself — the LLM can help you vibe-code a naive search script as the need arises.
Tips and tricks
Obsidian Web Clipper is a browser extension that converts web articles to markdown. Very useful for quickly getting sources into your raw collection.
Download images locally. In Obsidian Settings → Files and links, set "Attachment folder path" to a fixed directory (e.g. raw/assets/). Then in Settings → Hotkeys, search for "Download" to find "Download attachments for current file" and bind it to a hotkey (e.g. Ctrl+Shift+D). After clipping an article, hit the hotkey and all images get downloaded to local disk. This is optional but useful — it lets the LLM view and reference images directly instead of relying on URLs that may break. Note that LLMs can't natively read markdown with inline images in one pass — the workaround is to have the LLM read the text first, then view some or all of the referenced images separately to gain additional context. It's a bit clunky but works well enough.
Obsidian's graph view is the best way to see the shape of your wiki — what's connected to what, which pages are hubs, which are orphans.
Marp is a markdown-based slide deck format. Obsidian has a plugin for it. Useful for generating presentations directly from wiki content.
Dataview is an Obsidian plugin that runs queries over page frontmatter. If your LLM adds YAML frontmatter to wiki pages (tags, dates, source counts), Dataview can generate dynamic tables and lists.Ảnh dưới bạn thấy tôi dán vào như này:
Prompt này hướng dẫn Claude hoạt động như một wiki maintainer có kỷ luật mô tả cách tổ chức wiki, cách xử lý tài liệu mới, cách trả lời câu hỏi dựa trên wiki thay vì tự suy luận. Đây chính là thứ biến Claude từ chatbot thông thường thành người quản lý bộ não cho bạn.

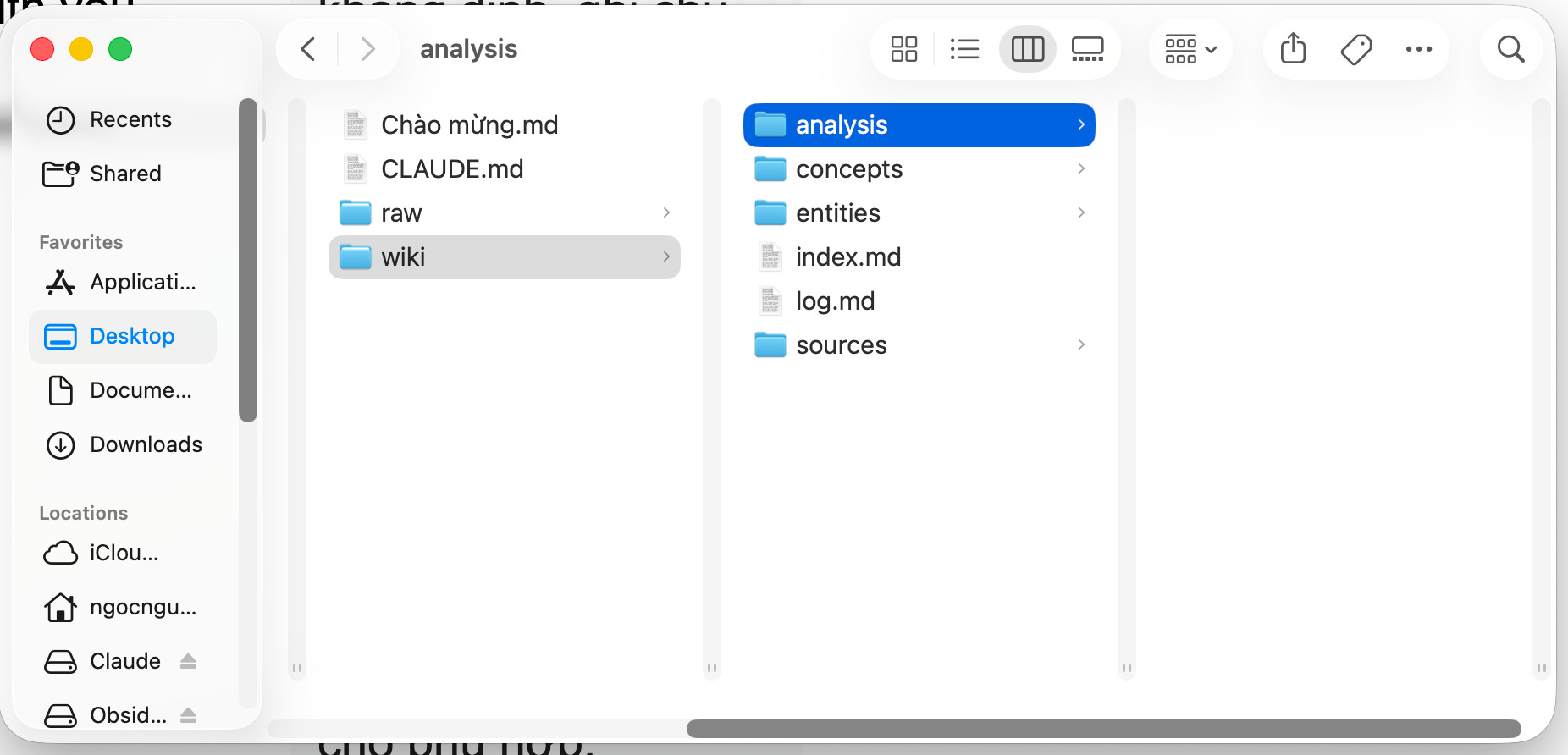
Sau khi gửi, Claude đọc vault (hiện còn trống) và hỏi bạn muốn làm gì. Chọn “Both” để thiết lập cấu trúc thư mục đầy đủ. Claude sẽ tự tạo ngay: file CLAUDE.md (schema hướng dẫn), thư mục `raw/` (chứa tài liệu nguồn của bạn), thư mục `wiki/` (nơi AI tạo và quản lý — với index.md, log.md, và các subfolder).
Bộ não đã có khung xương rồi

Bây giờ thử mở thư mục trên desktop tôi đã thấy mọi thứ xuất hiện
Bước 4: Nạp dữ liệu đầu tiên - phần quan trọng nhất
Vault trống là vault vô dụng. Bạn cần cho nó “nuốt” dữ liệu. Có ba cách tôi hay dùng:
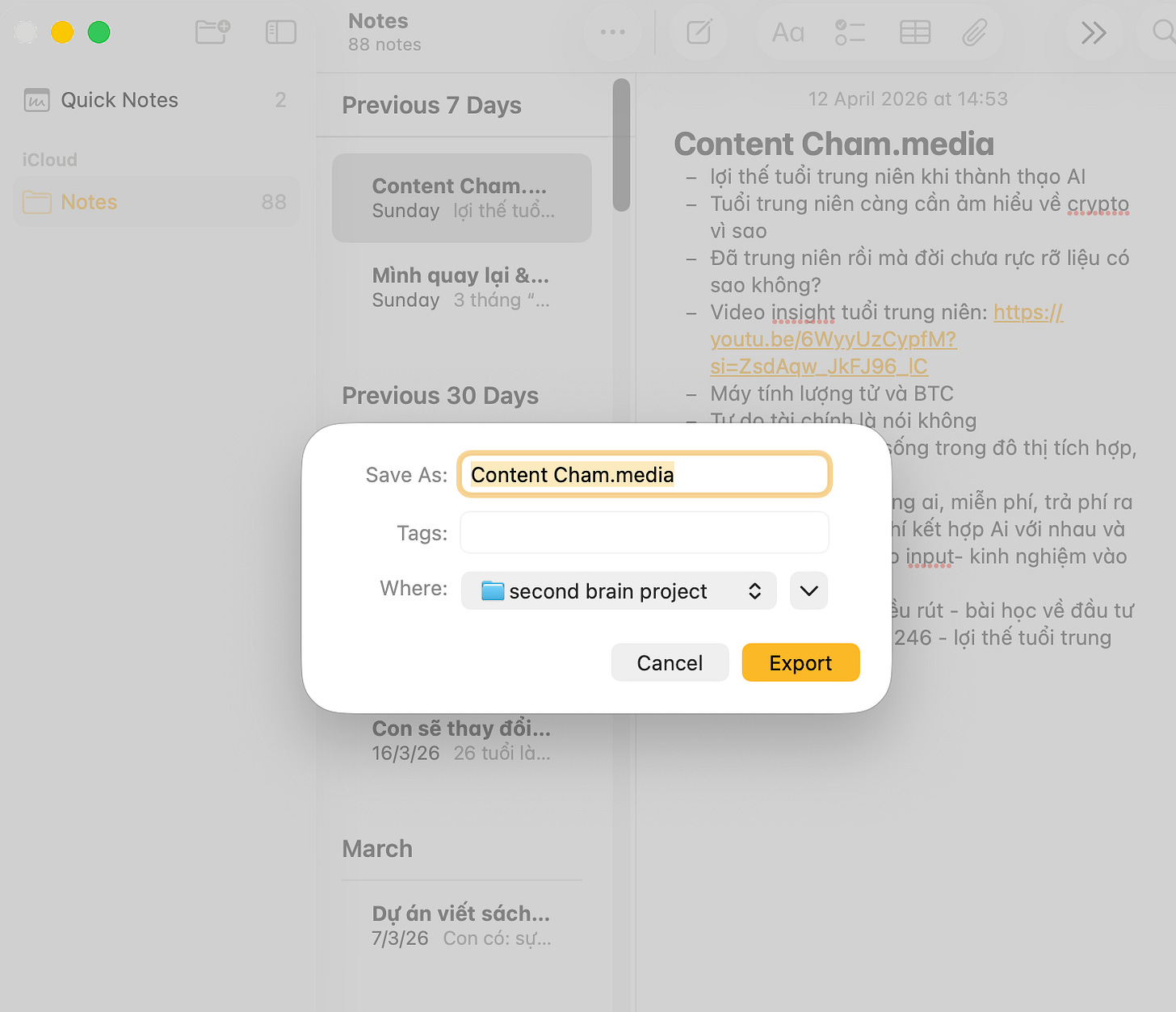
Từ ghi chú sẵn có: Export các note quan trọng từ Apple Notes, Notion, hay bất kỳ ứng dụng nào bạn đang dùng ra file “.md” và bỏ vào thư mục “raw/”. Nếu dùng bạn Notion, export ra CSV cũng được
Từ web: Cài Obsidian Web Clipper (extension Chrome miễn phí tại obsidian.md/clipper). Khi đọc bất kỳ bài viết nào, click extension - nó tự chuyển thành markdown và lưu thẳng vào vault. Tôi dùng cái này để clip bài từ ngocdenroi.com (blog tôi đã viết liên tục 10 năm) và các nguồn tôi theo dõi thường xuyên.
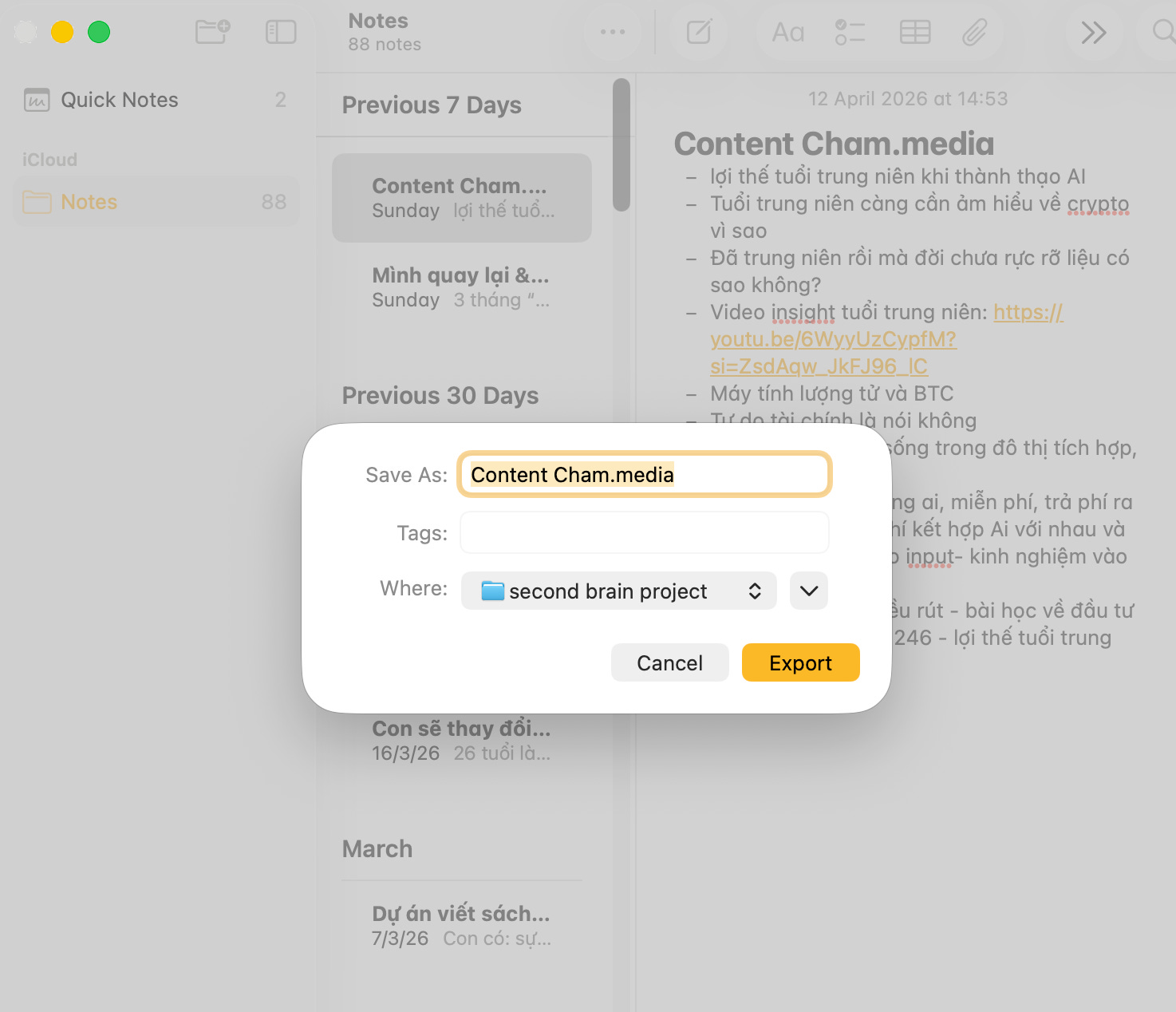
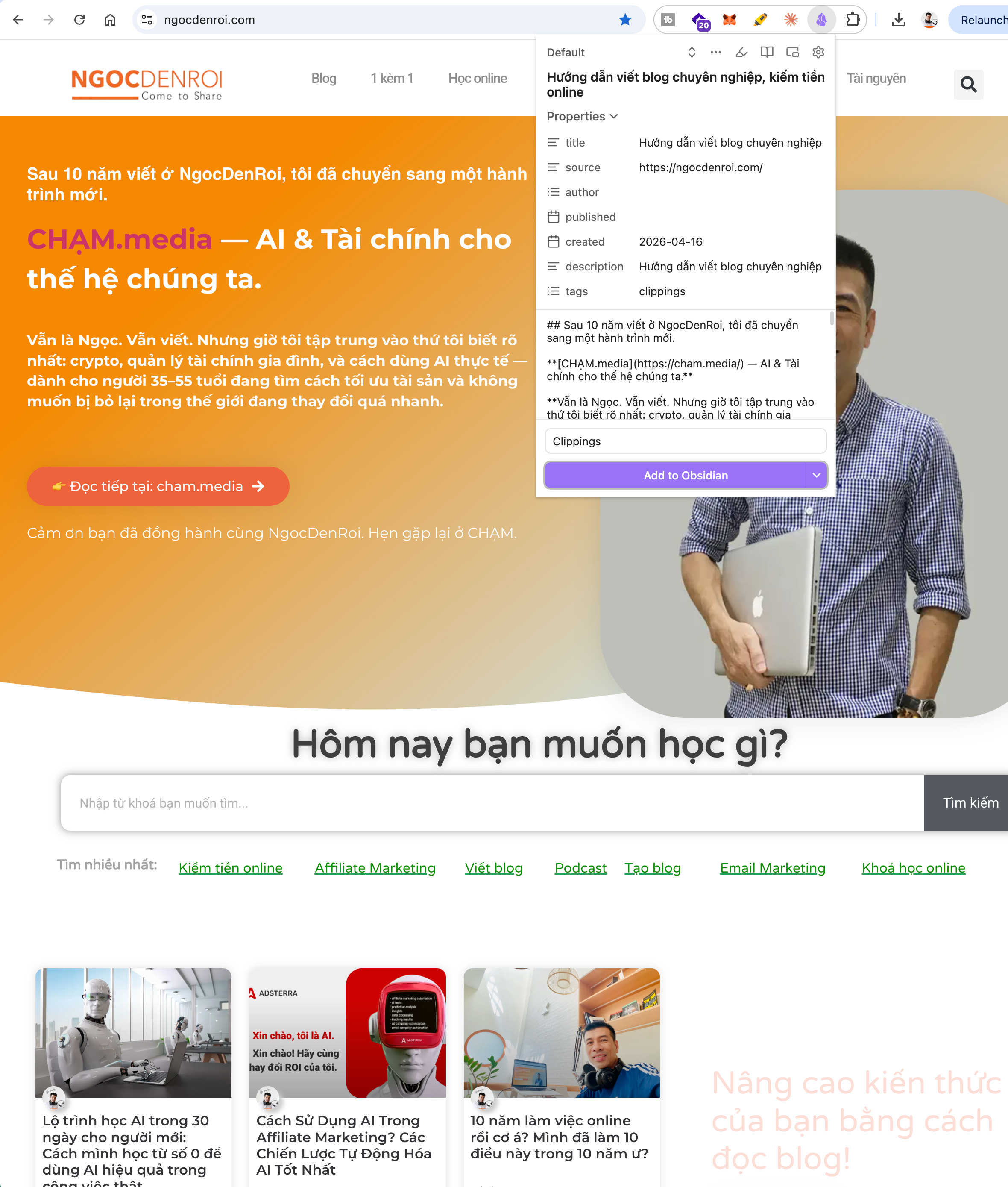
Từ cuộc trò chuyện với AI: Tôi nhờ Claude chat tổng hợp tất cả những gì tôi đã chia sẻ trong các cuộc trò chuyện trước đây, thông tin cá nhân, hành trình, dự án, giọng văn thành một file “ngoc-profile-raw.md”. File này trở thành nguồn thô đầu tiên và quan trọng nhất, vì khi Claude đọc nó, nó hiểu ngay tôi là ai mà không cần tôi giải thích lại từ đầu.
Kết quả chỉ sau 1 phút tôi có được file như ý:
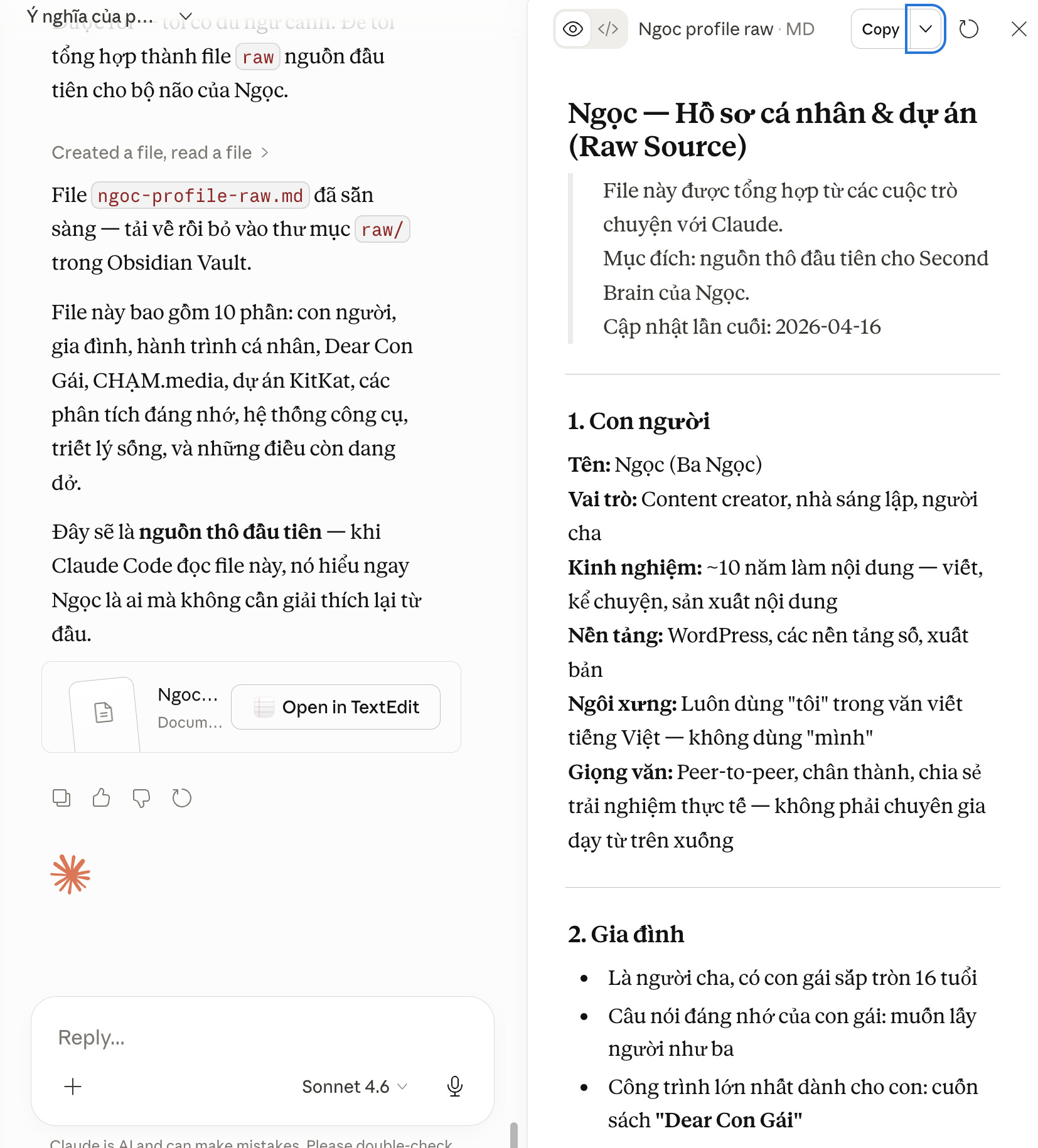
Tôi tải xuống file “ngoc-profile-raw.md” vào thẳng thư mục “raw/”:
Nhưng chưa hết, bây giờ cần phải làm cho AI nó “nuốt” file này…
Bước 5: Ra lệnh “Ingest - ăn/nuốt” và để AI làm phần còn lại
Sau khi có file trong `raw/`, quay lại Claude và gõ:
“Này tôi vừa nhập khá nhiều thông tin vào Obsidian, làm ơn hãy nhập dữ liệu này vào Wiki của tôi.” hoặc
Đọc file [tên file] trong thư mục raw và cập nhật vào wiki
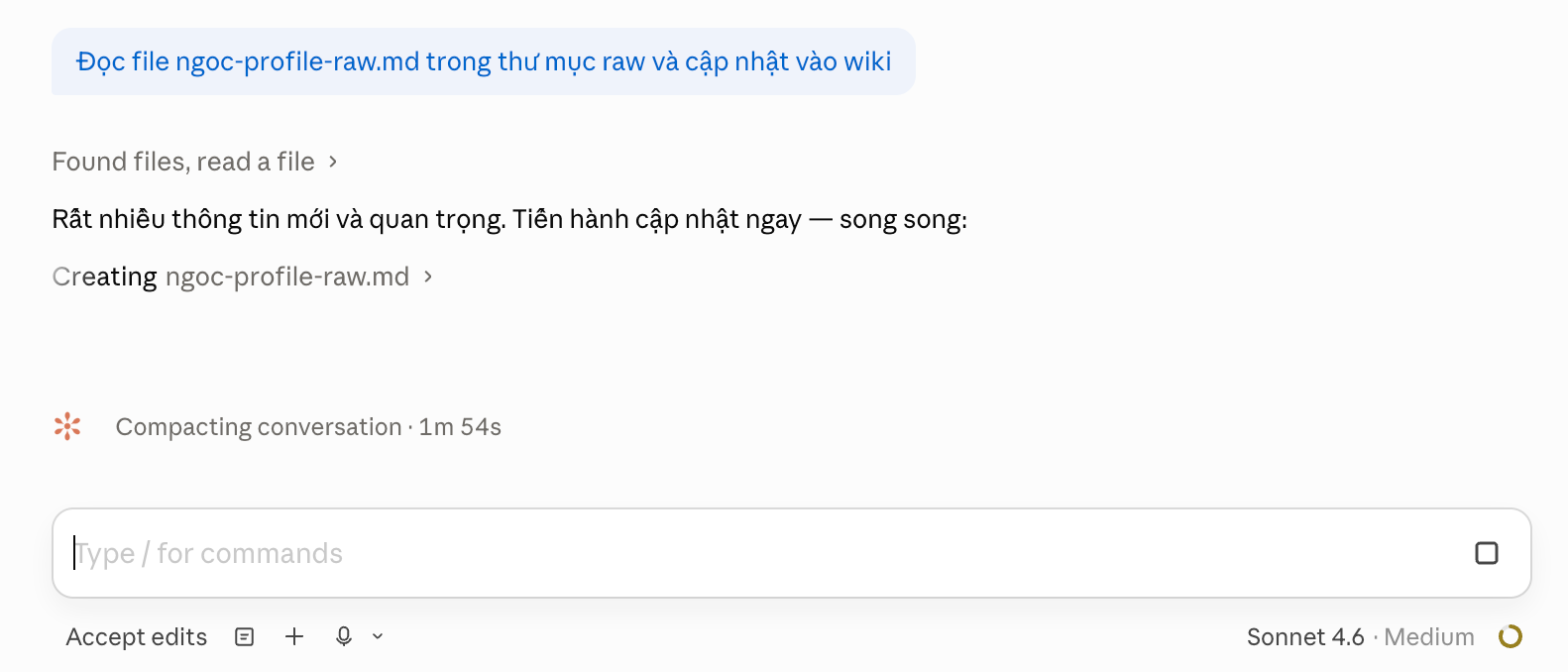
Claude sẽ tự tìm tất cả file mới, đọc song song nhiều file, tạo các trang wiki phù hợp về bạn, về dự án, về các chủ đề rồi cập nhật index.md, log.md, và kết nối ý tưởng với nhau.
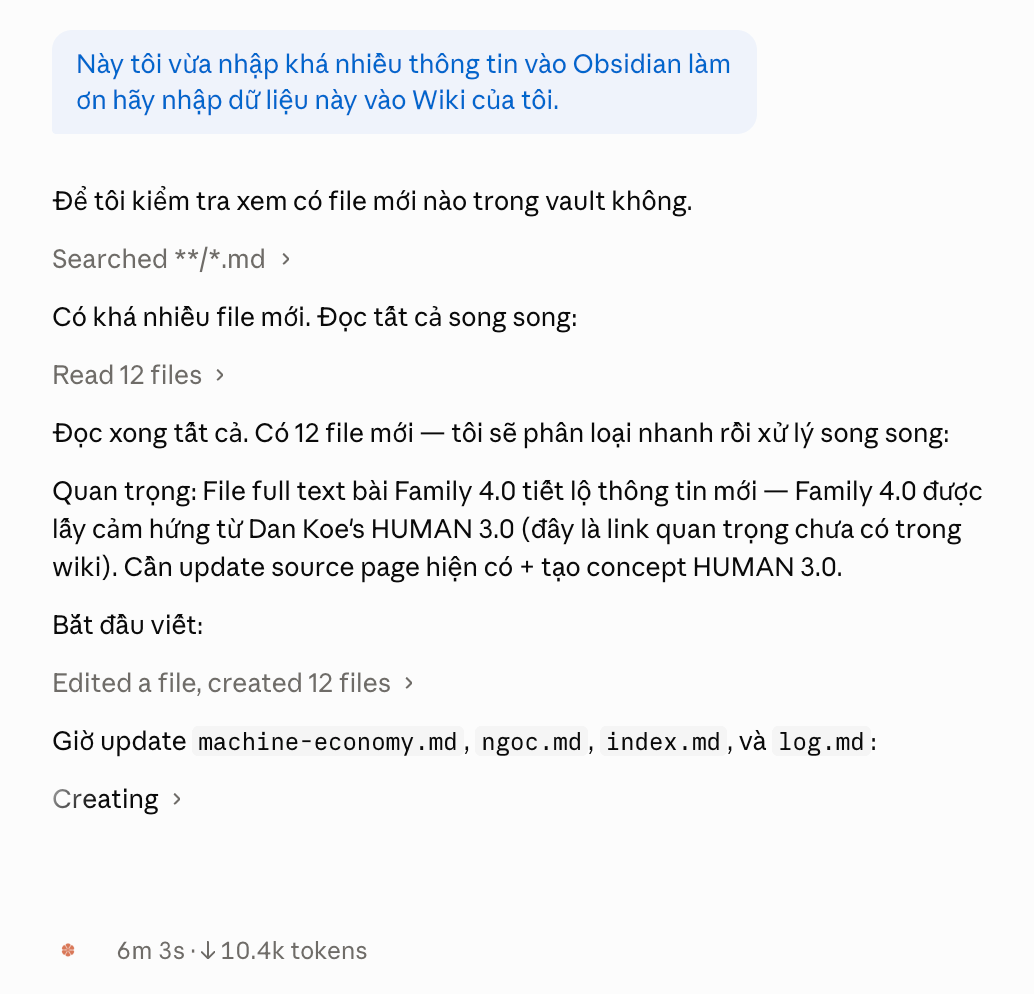
Điều thú vị nhất tôi thấy trong lần cho Claude code nuốt file đầu tiên là: khi Claude đọc file kế hoạch nội dung CHẠM.media, nó phát hiện trong đó đề cập đến cuốn sách “Lợi thế trung niên” và “HUMAN 3.0” của Dan Koe (tôi từng đọc & tham khảo để phát triển mô hình FAMYLY 4.0) rồi chủ động ghi chú rằng đây là “nguồn quan trọng chưa có trong wiki”, cần tạo thêm trang cho khái niệm này.
Nó không chỉ lưu trữ, nó thật sự hiểu.
Sau khi setup xong, bạn có thể làm gì?
Khi wiki đã có dữ liệu, bạn có thể hỏi Claude bất kỳ điều gì dựa trên toàn bộ context về bản thân:
“Tóm tắt tất cả ý tưởng nội dung tôi đã ghi liên quan đến crypto và gia đình.”
“Tìm những điểm mâu thuẫn trong các kế hoạch kinh doanh tôi đã viết.”
Tôi đã thử với prompt: “Dựa trên tất cả thông tin trong wiki/, ba điểm thiếu sót lớn nhất trong hiểu biết của tôi về [chủ đề] là gì?

Ngay sau đó bộ não thứ 2 quét dữ liệu wiki và cho tôi kết quả:

Nhưng điểm quan trọng nhất không phải là những câu hỏi bạn có thể hỏi mà là câu trả lời được lưu lại thành wiki page mới. Tức nó còn đề xuất nghiên cứu thêm và “nuốt” tiếp dữ liệu mới vào trang wiki
Nói chung hội thoại của tôi sẽ không biến mất vào lịch sử chat nữa. Mỗi phân tích giá trị, mỗi kết nối ý tưởng bạn khám phá đều góp phần làm giàu thêm bộ não. Hệ thống tự cải thiện theo thời gian.
Hoặc với prompt này: “Tạo cho tôi một mega-prompt tóm tắt đầy đủ về tôi để dùng trong ChatGPT.”
Đây là một use case rất thực tế mà tôi thấy ngay: tạo mega-prompt cho các cuộc trò chuyện AI khác. Thay vì giải thích từ đầu trong ChatGPT hay Gemini, tôi hỏi wiki một câu rồi dùng output đó làm context. Không mất thêm 5-10 phút giải thích nữa.
Bảo trì bộ não hàng tháng (phải làm)
Đây là việc rất quan trọng, việc này giúp phát hiện lỗi trước khi chúng trở nên nghiêm trọng. Nếu AI đưa thông tin hoặc viết sai một chút và bạn lưu lại, câu trả lời tiếp theo sẽ dựa trên lỗi đó. Quá trình kiểm tra trạng thái hoạt động chính là khâu kiểm soát chất lượng bộ não của bạn.
Vì thế mỗi tháng bạn nên chọn 1 ngày cố định và bảo trì bộ não bằng prompt:
“Xem xét toàn bộ thư mục wiki/. Đánh dấu các điểm mâu thuẫn giữa các bài viết. Tìm các chủ đề được đề cập nhưng chưa được giải thích. Liệt kê các tuyên bố không có nguồn chứng minh trong thư mục raw/. Đề xuất 3 bài viết mới để lấp đầy những khoảng trống.”
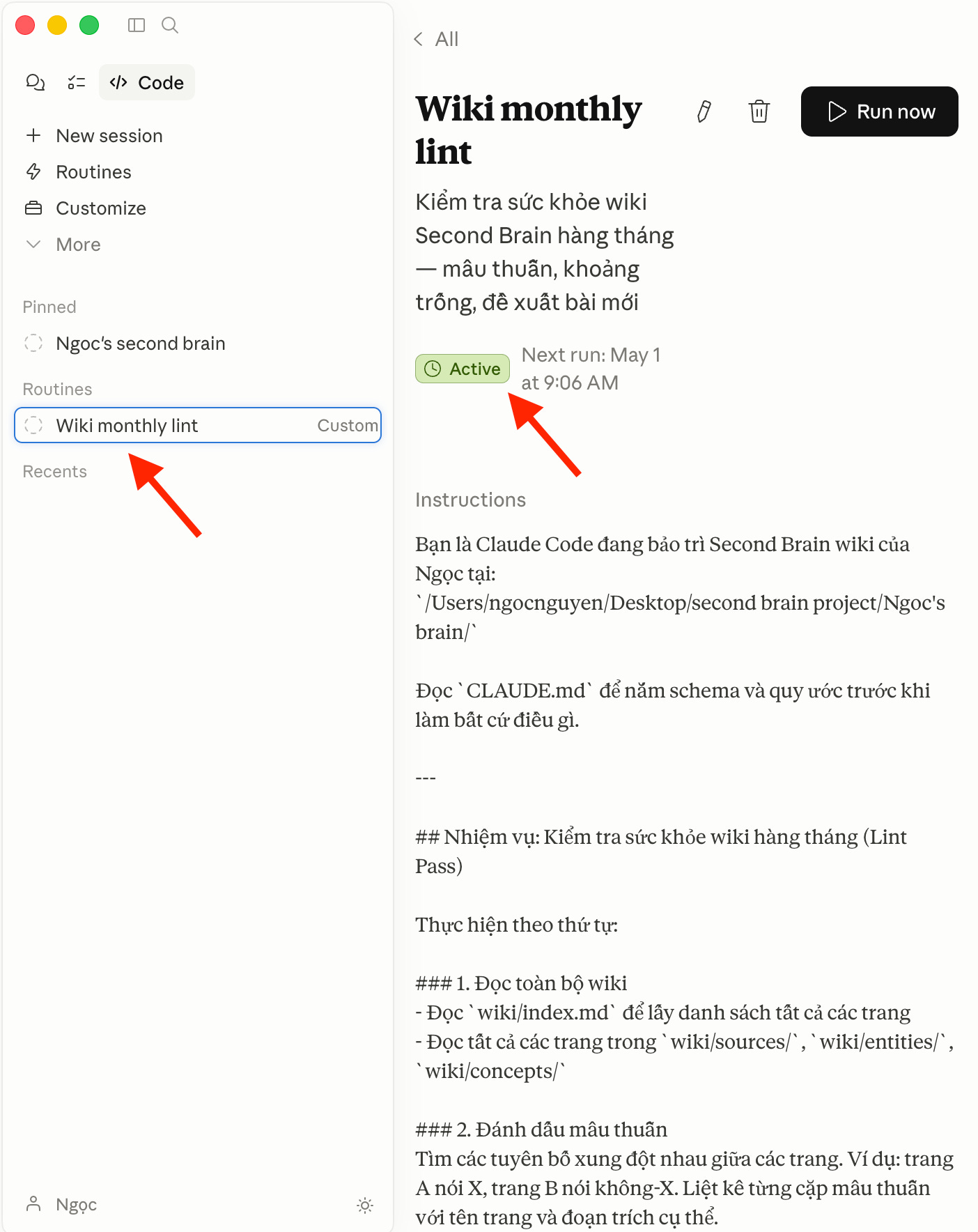
Cá nhân tôi thì tạo hẳn một tác vụ bảo trì & lên lịch tự động qua chức năng “Routines” của Claude Code. Tác vụ này được chạy tự động vào ngày 1 hàng tháng. Như vậy bộ não thứ 2 của tôi luôn được “nuôi dưỡng & làm mới”
Vài điều cần biết trước khi bắt đầu
Không phải ai cũng cần hệ thống này. Nếu bạn không có nhiều ghi chú hoặc ý tưởng cần quản lý, đây có thể là công cụ quá phức tạp so với nhu cầu thực tế.
Bạn cần chủ động nạp dữ liệu. Vault trống là vault vô dụng. Giá trị của hệ thống tỉ lệ thuận với lượng dữ liệu có ý nghĩa bạn đưa vào. Đây không phải thứ bạn cài xong rồi tự chạy, nó cần sự đầu tư ban đầu.
Bộ não thứ 2 sẽ đọc toàn bộ nội dung trên wiki của bạn và đưa ra câu trả lời dựa trên chính những tài liệu bạn đã thu thập.
Việc của bạn là lưu các câu trả lời đó vào trở lại vào kho kiến thức. Đưa kết quả vào thư mục “raw/” hoặc để AI cập nhật bài viết wiki liên quan với thông tin mới. Mỗi câu hỏi, mỗi kết quả đều giúp cho câu trả lời tiếp theo tốt hơn. Một vòng lặp làm cho bộ não thứ 2 ngày càng thông minh hơn.
Ngoài ra, bạn có thể tải ứng dụng Obsidian trên điện thoại, sau đó đồng bộ với app trên máy tính. Từ đó bất kể khi nào lúc bạn đi bộ, ngồi uống cafe, đi du lịch nhìn thấy cái gì đó ý nghĩa… bạn có thể đưa ngay dữ liệu này vào “raw/”
Kết
Tôi xây dựng bộ não thứ 2 này trong 30 phút. Vault “Ngoc’s brain” giờ có cấu trúc rõ ràng, có profile cá nhân, có kế hoạch nội dung CHẠM.media, có các bài viết từ ngocdenroi.com được tổ chức thành wiki có liên kết với nhau. Có cả những gì tôi đọc, nghe, nhìn, cảm nhận được mỗi ngày đều được nhập vào kho dữ liệu thô của bộ não.
Lần tới khi tôi mở Claude code và nói: “Tôi muốn viết bài về X”, nó đã biết tôi là ai, tôi đã viết gì, tôi đang hướng đến đâu. Không cần giải thích lại nữa.
(Sự thật bài viết này cũng được viết bởi bộ não thứ 2, tôi chỉ cần nói “hãy dựa vào quá trình tôi & bạn đã thiết lập Ngoc’s second brain, sau đó viết một bài cho CHAM.media hướng dẫn thật chi tiết theo phong cách step-by-step”)
Khi tôi quay lại thì bài viết đã xong và được lưu gọn gàng trên Google Drive:
Bạn có thể bắt đầu ngay hôm nay với 5 file ghi chú nhỏ nhất của mình. Rồi thêm dần. Bộ não thứ hai không cần hoàn hảo từ ngày đầu, nó chỉ cần bạn bắt đầu.
Nếu bạn thử và thấy thú vị hoặc gặp khúc mắc ở bước nào, tôi rất muốn nghe.
Thank you so much 😘
Anh cho em hỏi, nếu em thay đổi tài khoản claude bằng tài khoản Claude khác hoặc thay bằng codex (giống claude code) thì bộ nhớ của Brain có bị ảnh hưởng không anh.